If You're Building Enterprise AI Agents, Start With a Morning Brief
Advice from building enterprise-grade agent systems on why the morning brief is the best first agent to ship, what teams get wrong, and the design rules that make people trust it.
May 01, 2026
If I were building the first AI agent inside an enterprise, I would not start with the most ambitious workflow. I would not start with the agent that can take the most actions. I would not start with the demo that looks magical. I would start with a morning brief. That sounds smaller than it is.
But after building agent systems in enterprise environments, I now think this is one of the highest-leverage first agents a team can ship. Not because it is flashy. Because it solves a problem people already feel every day.
Before most people begin the actual work, they have to reconstruct the context of the work. They reopen Slack/Teams/Mattermost. They scan threads. They check tickets. They read dashboards. They look at docs. They try to remember what changed after they logged off. They figure out which decisions are waiting on them and which things are just noise. That reconstruction tax is everywhere. And most teams underestimate how expensive it is.
The first mistake
When teams start building agents, the first question is usually:
What can we automate?
I think that is the wrong first question.
The better question is:
Where are people losing time every day before they even get to the real work?
In most enterprise environments, the answer is not execution.
It is context. People are not usually blocked because they are incapable of making decisions. They are blocked because the information needed to make the decision is scattered across five systems. The first agent people trust is rarely the one that acts on their behalf. It is the one that helps them see clearly. That is why the morning brief matters.
What the brief is actually doing
A morning brief is not a chatbot. It is not a dashboard. It is not a generic summary of everything that happened. It compresses context.
The useful version answers four questions:
- What changed since I last checked in?
- What is blocked and needs me?
- What is coming due soon enough that I should prepare now?
- What looks abnormal enough that I should inspect it myself?
That is it. The discipline is important. Once the brief tries to answer everything, it becomes another inbox. Another surface area. Another thing to read before the work can begin. A good morning brief should reduce the number of things competing for attention. Not increase it.
Why this is the right first agent
The morning brief works well as a first enterprise agent because it is useful before it is autonomous. It does not need to issue refunds. It does not need to close tickets. It does not need to update customer records. It reads, ranks, drafts when useful, and stops. That stopping point matters more than teams realise. In enterprise systems, trust is not built by showing that the agent can do everything. Trust is built by showing that the agent knows where to stop. A morning brief has another advantage: the value is easy to feel. If someone used to spend 45 minutes reconstructing context and now spends 7 minutes reviewing a brief, they do not need a strategy deck to understand the benefit. They feel it.
The best internal tools usually work this way. They make one painful thing obviously less painful. The failure mode is also more manageable. If the brief misses something, that is a problem. It should be fixed. But it is not the same as an agent taking the wrong action across hundreds of customers, vendors, or internal records. Trust compounds slowly. One bad autonomous action can destroy more trust than fifty good summaries build.
Summarization is not enough
The most important thing we learnt is that a useful morning brief is not just a summary. It has to rank. It has to decide what matters. It has to show sources. It has to make uncertainty visible. It also has to be short enough that a busy person will actually read it.
Nobody reads long agent output, even when it is accurate. Accuracy matters. But usefulness depends on compression. A good brief has a point of view about what deserves attention. Not a personality. Not motivational language. No hedging.
A bad brief says:
Here is a summary of everything that happened across your workspace.
A good brief says:
These are the five things that matter before your 10am review meeting.
That difference is the product.
What good output looks like
The useful version is short, ranked, and tied back to sources. For example:

That is the shape. Short. Ranked. Source-linked. Clear about what needs action and what does not. From my experience, a good agent should not only tell me what to look at. It should also tell me what I can ignore. That is where the cognitive load drops.
The architecture should be boring
The morning brief does not need a complex multi-agent architecture on day one. I would start with a boring pipeline: pull from a small number of systems, retrieve updates since the last check-in, deduplicate repeated information, rank by importance and ownership, generate the brief, link important claims back to sources, and collect feedback on what was useful, noisy, or wrong.
The hard part is not the pipeline. The hard part is ranking. Which thread matters? Which metric movement is real? Which item needs a decision? Which source should be trusted more? Which item is urgent but not important? Which item looks scary but can wait? That is where the agent/product quality lives. Like most teams, we were over-focused on the language model output.
Instead of asking:
Is the summary well written?
That is useful, but not enough.
The better question is:
Did the agent choose the right things to summarize?
In a morning brief, ranking quality matters more than prose quality. A beautifully written brief with the wrong five items is useless. A slightly rough brief with the right five items is useful immediately. That distinction matters when you build the evaluation layer. You should not only evaluate whether the generated text is accurate. You should evaluate whether the agent surfaced the right items in the first place.
The most important feedback signal is not whether people say they like the brief. It is whether they change their behavior. Do they read it before opening Slack? Do they use it before meetings? Do they forward parts of it to other people? Do they rely on it when preparing for reviews? That is when you know it is becoming part of the workday.
The mistakes I would avoid
The first mistake is making the brief too long. If the brief has 18 items, the agent has failed. It has summarized, but it has not ranked. Coverage is not the point. Clarity is.
The second mistake is hiding the sources. A morning brief without source links is asking for blind trust. In enterprise systems, that rarely works. People need to verify the chain of reasoning, especially in the early days. No source, no trust.
The third mistake is making it sound too polished. Teams often try to make the agent sound impressive. But people do not need impressive. They need useful. A morning brief should sound like an extremely organized chief of staff with zero ego. Clear beats clever.
The fourth mistake is starting with autonomous actions. The temptation is obvious and I fell into this trap. I would resist that early. Let it read first. Then let it rank. Then let it draft. Then let it recommend.
Only after that should it act, and only inside tight boundaries. Each step earns trust for the next one.
The fifth mistake is ignoring permissions. The brief may look harmless because it is “just summarizing.” But retrieval is access. If the agent can read sensitive customer data, employee data, financial data, or internal strategy, then the brief is not just a productivity feature. It is part of your security and compliance surface area. Design it that way from day one.
The controls matter
Before shipping a morning brief in an enterprise environment, I would want clear answers to a few questions. Which systems can the agent read from? Can every important claim be traced back to a source? Can users mark an item as useful, noisy, or wrong? What happens when the agent flags something high-risk? How do we know whether ranking is improving? What categories should never appear in an automated brief? This is the part that separates a demo from a system. The demo only has to look right once. The system has to be useful every morning.
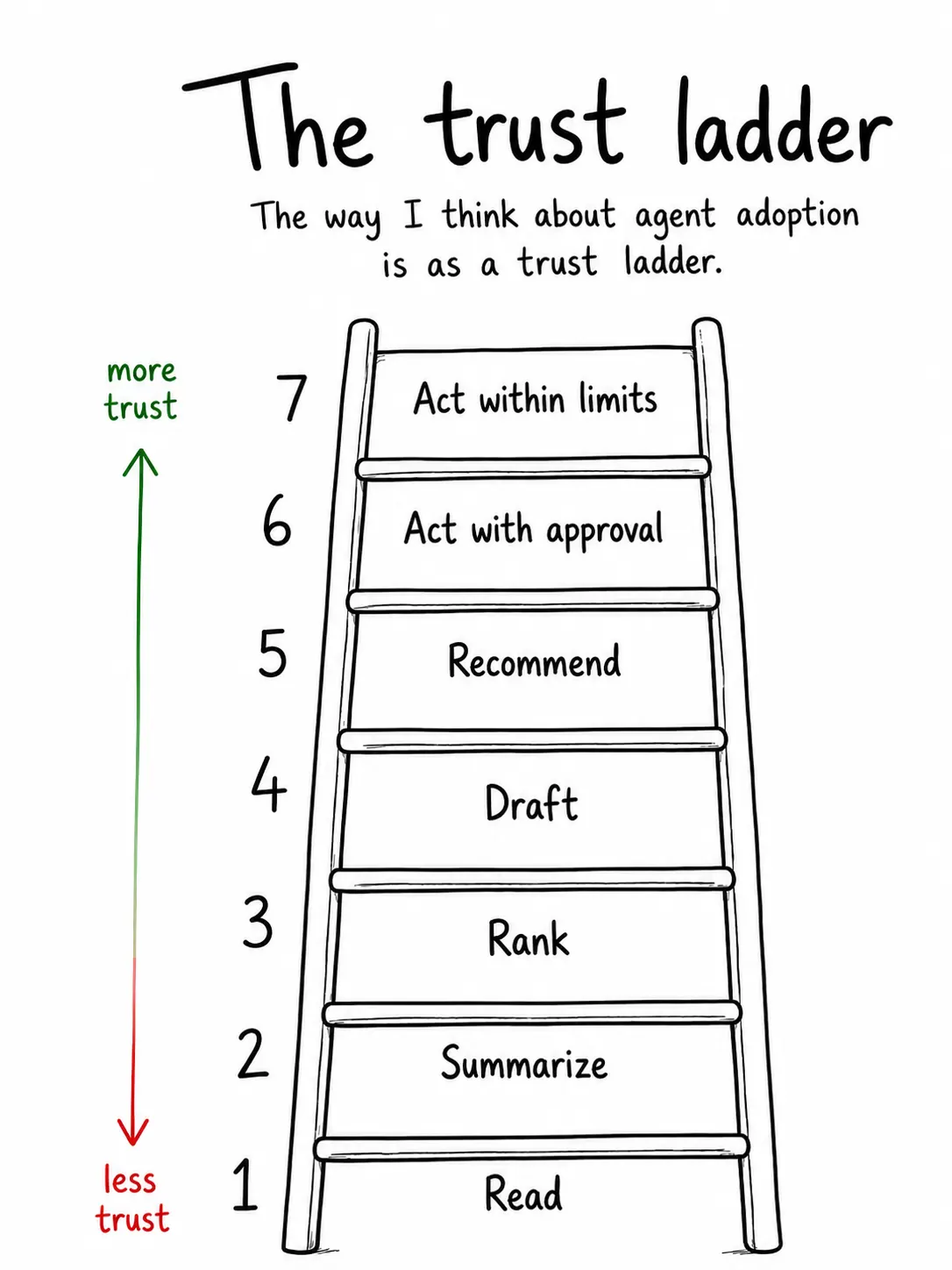
Most teams want to jump straight to the action parts, level 6 or 7. That is usually a mistake. The morning brief starts on the left side of the ladder. It reads. It summarizes. It ranks. It drafts only when useful. That is why it is such a good first agent. It builds trust without asking for too much trust upfront.
Why this changes meetings
One of the best second-order effects of a morning brief is what it does to meetings. A lot of standups and reviews are not really decision forums. They are context reconstruction rituals. People spend the first half of the meeting telling each other what already happened. When the brief works, the meeting changes. People walk in with shared context.
The discussion moves from:
What happened?
to
What do we do now?
That is a much better use of human time. The exact minutes do not matter. The direction matters.
Roadmap for builders
If I were advising a team starting today, I would build it in four phases.
Phase 1: Read-only brief
Start with a small number of systems. Slack. Jira. Email. Docs. One dashboard. Do not make it act yet. Do not make it update records yet. Just make it useful.
Phase 2: Source-linked ranking
Once the brief is generating useful summaries, improve the ranking. Add source links. Add confidence levels. Add short “why this matters” notes. Add feedback for useful, noisy, and wrong. This is where the system starts learning what each person or role actually cares about.
Phase 3: Draft assistance
Once people trust the brief, let the agent draft follow-ups. This massively removes the initial friction. A vendor response. A launch-risk note. A support escalation summary. But keep the human in control. The draft should be 70% done, never final.
Phase 4: Bounded actions
Only after the first three phases work would I consider actions. And often, they wont work as expected in a single iteration. Building agents is hard. Keep the actions bounded. Create a follow-up task, tag a ticket, add a note to CRM, schedule a reminder. Do not begin with high-stakes actions. Earn the right to act.
A good first version is not fancy. It should be short, source-linked, respectful of permissions, honest about uncertainty, and able to improve with feedback. It does not pretend to know everything. Use humans for that. Most importantly, it stops before taking risky actions.
This is not glamorous product work. But it is the kind of work that makes enterprise agents real. If you are building enterprise agents, I would not begin by asking how much autonomy you can give the system. I would begin by asking where better context would immediately improve human work. The morning brief is a strong answer because it is useful, bounded, and trust-building. It does not ask the organization to believe in a fully autonomous future. It just makes tomorrow morning better. That is how enterprise agents should start.
Small surface area, clear value, human control.
A system that earns trust before it asks for more responsibility is what worked for us.